
Apache Kafka is a pub-sub tool that is commonly used for message processing, scaling, and handling a huge amount of data efficiently.
Whereas Java Message Service aka JMS is a message service that is designed for more complicated systems such as Enterprise Integration Patterns.
Both Apache Kafka and JMS-based services have been pretty successful and helped the organizations to effectively communicate through servers to the internal teams and customers alike.
Our primary focus in this blog is to understand how these tools differ from each other in detail.
Key Differentiating Factors Between Apache Kafka and JMS
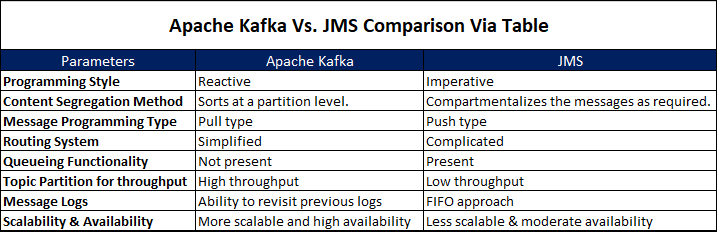
The key differentiator between Apache Kafka and JMS is their programming styles. Apache Kafka is a reactive programming style while on the other hand, JMS is an imperative programming style.
In the case of Apache Kafka, its system sorts the messages in the same order as they were sent from the partition level. But, in the case of JMS, such provision is not present, so you need to compartmentalize the messages as per the requirement.
Another factor which proves to be a key differentiator between Apache Kafka and JMS is the type of the messages.
Apache Kafka is a pull-type messaging platform where consumers pull the messages from the broker while JMS-based services are of push-type in nature where the providers push the messages to the consumers.
Also Read: SQL Vs. NoSQL Vs. NewSQL: What's The Difference?
In Apache Kafka, you cannot set the filters for exact terms at the broker level. If you want to set up the filters, you need to work that at the application level in Apache Kafka.
But, on the other hand, you can set the desired filters through JMS Message selectors. This functionality reduces an additional step of application-level filtering.
Apache Kafka allows you to have a simplified and easy routing system; while JMS has a little complicated routing system due to its system design.
Messages are stored for a defined amount of time in Apache Kafka irrespective of whether they are received by the consumers or not.
And on the other hand, JMS provides the disk or in-memory based storage facility. And once the message read, it gets permanently deleted.
Apache Kafka doesn’t allow you the queuing facility. The only way to send the messages is through the pub-sub model. But with JMS-based systems, you can queue up the messages through its routing system.
Apache Kafka allows you the functionality to segregate the topics as independent portioned logs. It ensures a high throughput for Kafka.
But, in the case of JMS-based tools, the segregation is not done in a sequential manner. This leads to lower throughput in the case of JMS-based tools.
Apache Kafka implements a system that allows the brokers to determine which message to read first unlike in the case of JMS.
JMS uses First in First Out approach due to the queuing functionality. The ability to revisit and choice of reading is an important benefit of Apache Kafka, which gives it an edge over JMS.
It is evident from the above-mentioned differences that Apache Kafka is more scalable in nature as compared to the JMS.
Also, the ability to auto-replicate the messages without compromising the simplicity results in the higher availability for Apache Kafka.
So Which One is Better: Apache Kafka or JMS?
Apache Kafka and JMS both are efficient tools, the key thing is to understand that the circumstances which help one of them to perform better than the other.
Apache Kafka is more suitable to handle a large volume of data due to its scalability and high availability while JMS systems are used when you need to work with multi-node clusters and highly complicated systems.
Also, Apache Kafka is used when there is a requirement of higher throughput (more than 100K/sec), and JMS is used when you need to work with the low throughputs.
JMS bases tools provide an HTTP API, CLI based operators that give JMS systems a faster deployment and ease of operation.
Apache Kafka uses partition-based operation with CLI and is more useful in the case of cases that require multiple changes in a short span.
You May Also Like to Read:


