
What is the Concept of Data Mining?
Data mining is the process to analyze the large sets of data for discovering new patterns, meanings, rules, correlations, anomalies, and predictions for futures. The term data mining is also known as “knowledge discovery in the database.”
Data mining is useful for future predictions or outcomes. Additionally, you can use data mining for building machine learning (ML) models, which power artificial intelligence (AI) apps such as search engine algorithms and recommendations for many applications like Netflix and Spotify.
Data mining is also crucial for statistics, which is a numeric study of data relationships.
The purpose of data mining is to extract information from the data sets which are available in the database and transform that information into a meaningful and structured process so that it could be helpful for any further use.
Now in this next step, we will figure out the process of data mining.
First, you need to collect data from various sources and integrate them into one portal (database). This data could be anything from useful to not-so-useful, qualitative to quantitative and continuous to discrete.
As in the first step, we collected the data for our database. Now in this step, we have to mark and select the most relevant data which we need to carry forward.
As we had collected the data from various sources. So there are chances that the data may contain some missing figures, errors, or inconsistency. So to get rid of that, we need to apply different techniques.
For proper modeling of data first, we need to create data sets. Each data set contains information about a particular subject. And, the immediate next step should be the testing of data to confirm its quality.
In this phase, data is evaluated in such a manner that it will meet the business objectives. Moreover, in this phase, some new business requirements may arise because of new data and information discovered from the process.
Gaining an understanding of business during the data mining process is a crucial part.
Now in this next part of the blog, we will understand some of the best techniques of data mining.
It’s near impossible to achieve data mining without having a proper data warehouse system in place. Data warehousing involves the structuring of data in the database for further usage like analyzing data for business intelligence, reporting, etc.
But the primary task of a data warehouse is to sort data, classify it, and set up metadata for easy recognition. In doing so, the data which is not crucial at that point is discarded.
Data classification refers to the categorization of different sets of data in different classes. This technique is like data clustering.
In clustering, data is segregated into various segments, but in data classification, data is segregated into classes.
Classification of data is a very crucial technique for data mining because once your organization identifies the main characteristics of data, then they can categorize the data as per their needs.
The clustering of data means combining those sets of data that are similar in nature. Let’s understand this by an example.
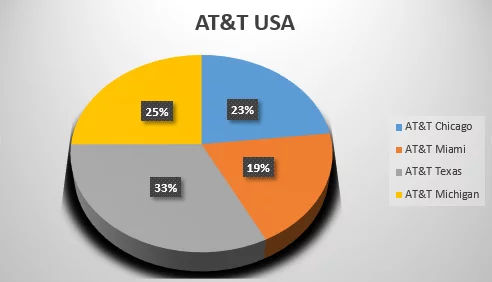
Suppose we are clustering KFC USA, so here, KFC Chicago will be one cluster, and the email IDs of employees in Chicago are the data of the same set which will come under the respective cluster.
By using the clustering mechanism, you can see your data in a graphical interface like pie charts and graphs. Like, in the below graph, AT&T USA is categorized into 4 clusters based on employees' strength.
Data cleaning is a crucial technique for data mining. The data which we gather for maintaining a database is known as raw data. And, this raw data must be cleansed and formatted for further use.
Data cleaning includes various elements of data modeling, migration of data from one cluster to another, ETL (Extract, Transform, and Load), data integration, and aggregation.
Clean data is self- equivalent to business growth. And, unclean data is unreliable, thereby meaningless for the organization.
The tracking pattern involves identifying the pattern of data usage and monitoring trends. And, by analyzing this, your organization can make better decisions.
The tracking pattern is a fundamental technique of data mining. So, let’s understand this by an example. Suppose your organization analyzes the sales trends for XYZ product in a particular demographic, which is performing well.
So, they could use a similar technique for another location where that product is not performing well.
Another crucial technique of data mining is regression. You can use this technique to identify the nature of the variables in the database.
This technique is also known as white-box technique, which reveals how the variables are related to each other. Moreover, this technique is also used for forecasting and data modeling.
Analytics is a major part of data mining, and prediction representing one of the four branches of analytics.
This technique is used to find the pattern between historical and present data, which helps you to make easy future predictions.
In many ways, you can use prediction techniques for data mining. But in the current scenario, it is used for artificial intelligence and machine learning.
A decision tree technique will help you to understand how the input of the data will affect the output or result of the analysis.
If you are combining different decision tree models for predictive analysis, then that process is known as the random forest.
A random forest test model is considered to be the most complicated amongst all because it’s tough to understand the output of it. This type of analysis is also known as a black-box machine learning technique.
A decision tree is a specific type of predictive model. Just to be more specific, the decision tree technique is a major part of machine learning (ML) and is commonly known as the white-box machine learning technique.
This model is very crucial for data mining and represents one of the main branches of artificial intelligence (AI). Analytics models, which are used for data mining, depend upon statistic data.
Where most of the other techniques are based upon data (past and present), the statistic model depends on probabilities, which make it to be one of its kind. The results of statistical techniques for data mining are more accurate than other techniques.
By this technique, you can analyze your data in a sequence. And, most importantly, understanding the technique of the sequential pattern would be key for your organization because it is not only helpful for data mining but also helps you to increase your sales.
What happens here is you get to analyze consumer behavior by understanding as to which particular products are being purchased together.
For example, you get to identify that a number of people who shop from your store, usually purchase shoes and socks in combinations.
This can help you draw some sort of inference for improving your sales strategy.
Data visualization is another crucial technique of data mining. Data visualization is the process which can help you see your data in a well-sophisticated presentation.
It allows you to understand your data in simpler ways like graphical representation, charts, images, or animation.
Currently, there are many data visualization tools available in the market, which can make your data easily understandable.
Some of them are Microsoft Excel, RapidMiner, R programming language, and many more.
Also Read:
Pentaho vs. Talend: How the Two Data Integration Tools Compare?


